Run Highly Efficient Multimodal Agentic AI with NVIDIA Nemotron 3 Nano Omni Using vLLM
We are excited to support the newly released NVIDIA Nemotron 3 Nano Omni model on vLLM.
Nemotron 3 Nano Omni, part of the Nemotron 3 family of open models, is the highest efficiency, open multimodal model with leading accuracy, built to power sub-agents that perceive and reason across vision, audio, and language in a single loop.
Enterprise agent workflows are inherently multimodal. Agents must interpret screens, documents, audio, video, and text, often within the same reasoning pass. Yet most agentic systems today bolt together separate models for vision, speech, and language, multiplying inference hops, complicating orchestration, and fragmenting context across the pipeline.
Nemotron 3 Nano Omni addresses two major challenges this fragmentation creates:
- Fragmented Models: Running separate vision, audio, and language models in sequence increases latency through repeated inference passes, amplifies cost and failure modes, and fragments context across modalities. Nemotron 3 Nano Omni collapses this into a single multimodal reasoning loop — one model that understands screens, documents, audio, and video simultaneously, simplifying agent workflow design and reducing orchestration overhead significantly.
- Efficiency: Continuous perception workloads — screen monitoring, document understanding, video analysis — demand sustained operation at scale. Nemotron 3 Nano's hybrid MoE architecture activates only 3B of 30B parameters per forward pass, delivers high throughput, and lowers compute for video reasoning via temporal-aware perception and efficient video sampling, enabling always-on agents to operate without prohibitive cost.
Using this model, an AI system will achieve 9x higher throughput than other open omni models with the same interactivity, resulting in lower cost and better scalability without sacrificing responsiveness.
TL;DR: About Nemotron 3 Nano Omni
- Architecture: Mixture of Experts (MoE) with Hybrid Transformer-Mamba Architecture
- Model size: 30B total parameters, 3B active parameters
- Context length: 256K
- Unified vision and audio encoders eliminate separate perception models — one model replaces fragmented multimodal stacks. 3D convolution layers (Conv3D) enable efficient handling of temporal-spatial data in video.
- Modalities:
- Input: text, image, video, audio
- Output: text
- Efficiency: Achieves 9x higher throughput than other open omni models with the same interactivity. Efficient Video Sampling (EVS) enables longer video processing at the same compute budget, delivering lower compute for video reasoning via temporal-aware perception. Supports FP8 and NVFP4 quantization for flexible deployment.
- Accuracy: 20% higher multimodal intelligence compared to the best open alternative.
- Post-training: Multi-environment reinforcement learning through NVIDIA NeMo RL and NeMo Gym across text, image, audio, and video environments, improving instruction following and convergence to correct multimodal answers.
- Supported GPUs: NVIDIA B200, H100, H200, A100, L40S, DGX Spark, and RTX 6000
Get started:
- Download model weights from Hugging Face — BF16, FP8, NVFP4
- Run with vLLM for inference using the cookbook and through Brev launchable
- Read the technical report for more details
Run Optimized Multimodal Inference with vLLM
Nemotron 3 Nano Omni achieves accelerated inference and serves more requests on the same GPU with BF16, FP8, and NVFP4 precision support. Follow these instructions to get started.
Install vLLM
pip install vllm[audio]==0.20.0Serve the model
You can serve Nemotron 3 Nano Omni via an OpenAI-compatible API. Set the attention backend and any required environment variables as needed for your setup. Refer to the cookbooks for detailed instructions for FP8 and NVFP4.
python3 -m vllm.entrypoints.openai.api_server \
--model "nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16" \
--served-model-name nemotron \
--trust-remote-code \
--dtype auto \
--host 0.0.0.0 \
--port 5000 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--media-io-kwargs '{"video":{"num_frames":512,"fps":1}}' \
--video-pruning-rate 0.5 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3Once the server is up and running, you can send multimodal prompts using the code snippet below.
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about GPUs."}
],
temperature=1,
max_tokens=1024,
)
print("Reasoning:", resp.choices[0].message.reasoning,
"\nContent:", resp.choices[0].message.content)For an easier setup with vLLM, refer to our getting started cookbook, available here or use NVIDIA Brev Launchable.
Highest Efficiency with Leading Accuracy for Multimodal Agentic Applications
Nemotron 3 Nano Omni is optimized for hardware‑efficient inference and integrates directly with modern inference stacks such as vLLM. It supports FP8 and NVFP4 quantization, NVIDIA‑optimized kernels, and efficient video sampling to deliver accurate, low‑latency, and predictable inference across deployment environments.
By combining these optimizations with 3D convolution‑based temporal‑spatial processing, Nemotron 3 Nano Omni sustains high‑quality multimodal perception at lower compute cost, enabling consistent accuracy and responsiveness from workstations to cloud‑scale systems.
Performance in Figure 1 is evaluated under fixed interactivity thresholds, holding per‑user token rates constant while measuring how much total system throughput can be sustained without degrading real‑time user experience for both multi-document and video use cases. This approach highlights efficiency without sacrificing responsiveness or quality under real deployment constraints, not just peak concurrency.
Multi-Document and Video Efficiency
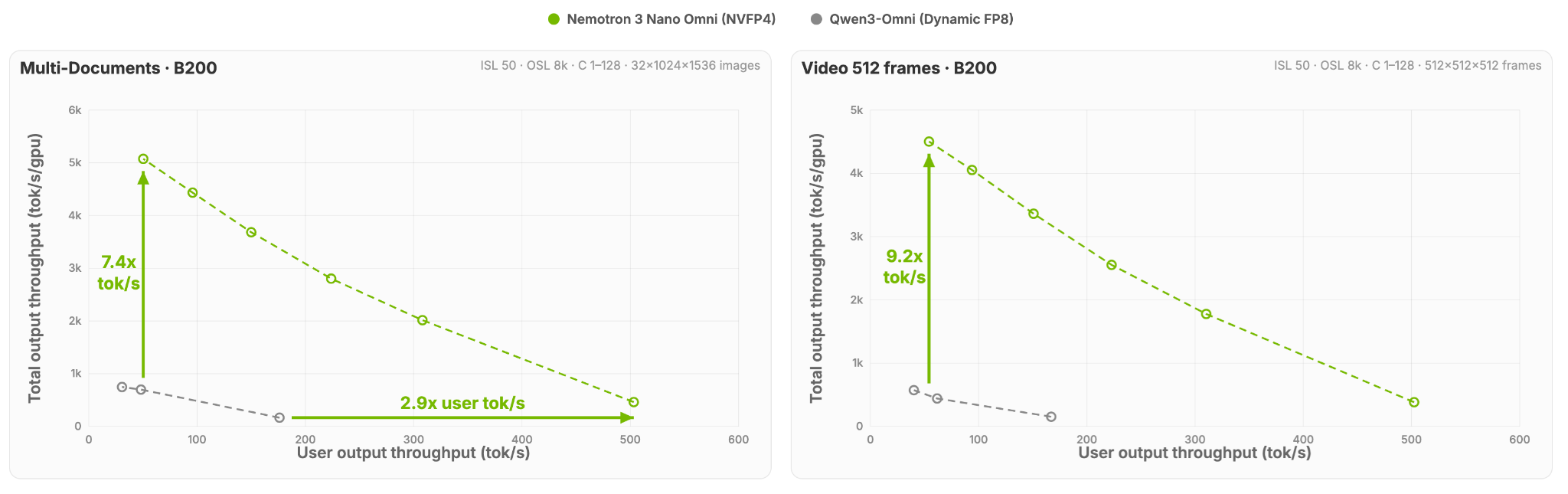
Figure 1: Total system throughput sustained by each model at a fixed per-user interactivity threshold (tokens/sec/user), showcasing a 7.4x and 9.2x higher throughput for multi-document and video use cases, respectively, for Nemotron 3 Nano Omni compared to an alternative open omni model.
Multimodal Accuracy
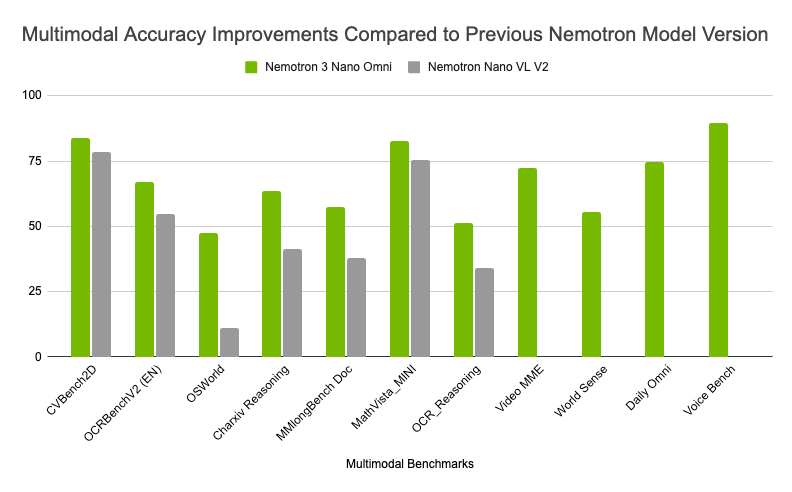
Figure 2: Improved multimodal reasoning accuracy across industry-leading benchmarks compared to the previous NVIDIA Nemotron Nano VL V2 model, highlighting strong performance across complex document intelligence, and video and audio reasoning.
As shown in Figure 2, Nemotron 3 Nano Omni has seen ongoing model improvements, delivering higher multimodal accuracy across vision, video, OCR, and audio benchmarks compared to the previous NVIDIA Nemotron Nano VL V2. These accuracy gains combined with leading efficiency have resulted in top placements across six multimodal leaderboards.

Figure 3: Nemotron 3 Nano topping six leaderboards for multimodal efficiency and accuracy.
The model delivers best‑in‑class performance on document intelligence benchmarks such as MMlongbench‑Doc and OCRBenchV2, while also leading in video and audio understanding benchmarks including WorldSense, DailyOmni, and VoiceBench. On the MediaPerf benchmark, Nemotron 3 Nano Omni achieved the highest throughput across every task and the lowest inference cost for video-level tagging.
In a system of agents, Nemotron 3 Nano Omni functions as the multimodal perception and context sub-agent, giving agents eyes and ears across screens, documents, audio streams, and video, while feeding structured understanding into orchestration and execution agents downstream. Its lightweight architecture allows it to run efficiently alongside other models in the system without duplicating compute across separate perception pipelines. It handles everything the agent needs to see and hear.
This makes Nemotron 3 Nano Omni a strong choice for powering computer use agents, document intelligence workflows, and audio-video understanding pipelines — all without the overhead of maintaining a fragmented multimodal stack.
Get Started
NVIDIA Nemotron 3 Nano Omni is an open multimodal model with highest efficiency that powers sub-agents to complete tasks faster across vision, audio, and language. With open weights, datasets, and recipes, you get full transparency and the flexibility to fine-tune and deploy on your own infrastructure, from workstation to cloud.
Ready to run multimodal AI agents at scale?
- Download model weights from Hugging Face — BF16, FP8, NVFP4
- Run with vLLM for inference using the cookbook and through Brev launchable
- Read the Nemotron 3 Nano Omni technical report
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.
Acknowledgement
Thanks to everyone who contributed to bringing Nemotron 3 Nano Omni to vLLM.
- NVIDIA: Nirmal Kumar Juluru, Anusha Pant
- vLLM team and community: Roger Wang, Michael Goin, Thomas Parnell, Kevin Luu, Robert Shaw, Tyler Michael Smith