Disaggregated Serving for Hybrid SSM Models in vLLM
·15 min read
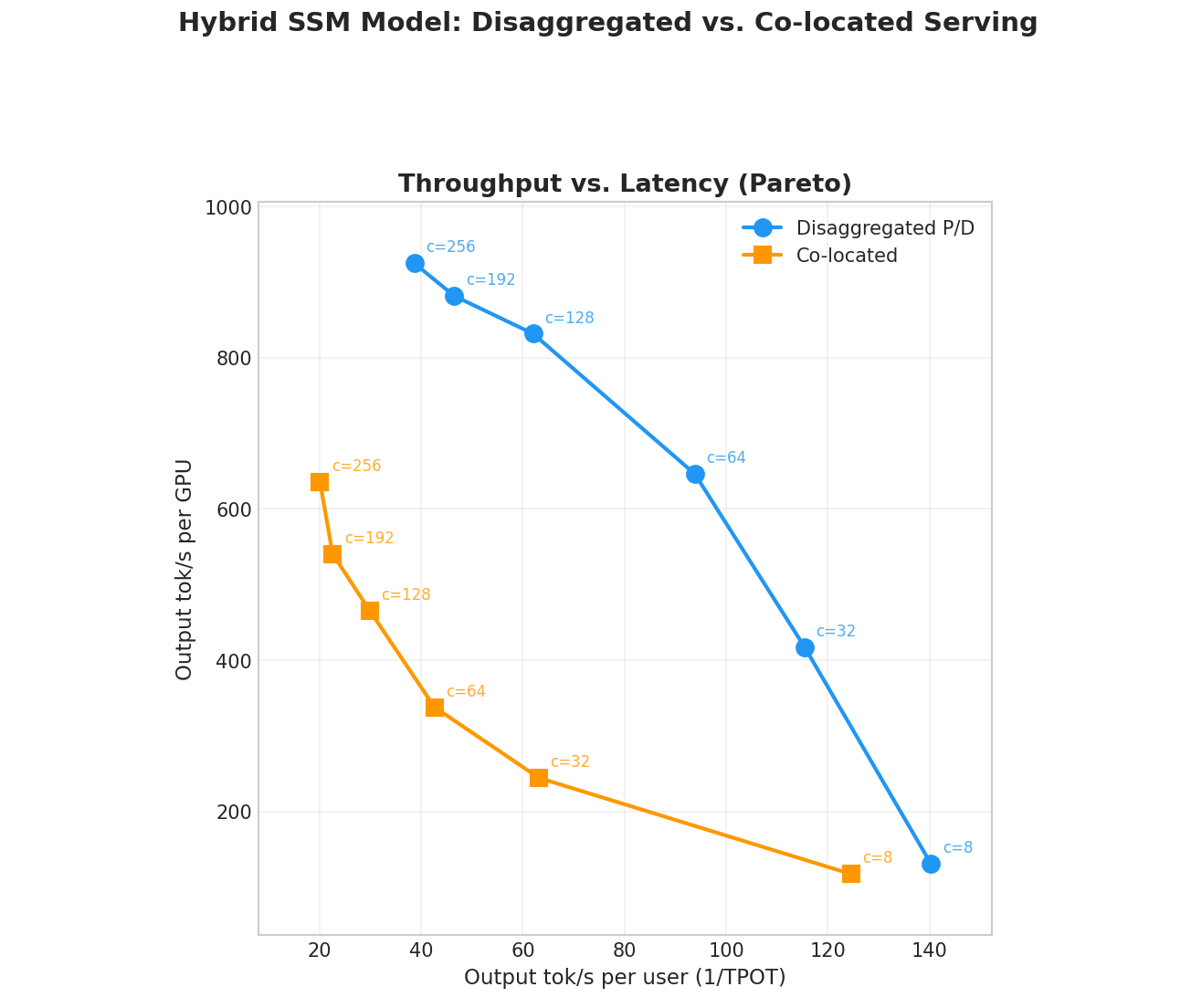
Hybrid architectures that interleave Mamba-style SSM layers with standard full-attention (FA) layers — such as NVIDIA Nemotron-H — are gaining traction as a way to combine the linear-time...