Disaggregated Serving for Hybrid SSM Models in vLLM
Introduction
Hybrid architectures that interleave Mamba-style SSM layers with standard full-attention (FA) layers — such as NVIDIA Nemotron-H — are gaining traction as a way to combine the linear-time efficiency of state-space models with the expressiveness of attention. vLLM already supports disaggregated prefill/decode (P/D) for standard transformer models through its NIXL-based KV connector: a prefill instance computes KV cache blocks and a decode instance pulls them over RDMA, eliminating redundant recomputation. But extending this to hybrid models is not straightforward. FA and SSM layers store fundamentally different state, in different layouts and different sizes, yet the block manager and NIXL connector were designed around a single, uniform KV cache format.
In this post we describe how we extended the NIXL connector to support hybrid SSM-FA models in disaggregated mode. The key ideas are:
- Dual descriptor views — two sets of NIXL block descriptors that index the same physical memory regions with different offsets and sizes, one for FA blocks and one for SSM blocks.
- Physical/logical block bridging — handling the mismatch between the logical block abstraction seen by the block manager and the physical block sizes required by attention kernels.
- 3-descriptor conv transfer — a decomposition of the Mamba conv state that enables heterogeneous tensor-parallel transfers without reshuffling data on the sender side.
None of these changes modify the existing workflow for standard transformer models. They are purely additive extensions that activate only when the model contains SSM layers.
This feature is available with vllm>=v0.20.0.
This work builds on the HMA interface for NIXL and spans several PRs:
- #36687 — Dual descriptor views and homogeneous-TP support for hybrid SSM-FA models
- #37416 — DS conv state layout for Mamba kernels
- #37635 — Heterogeneous-TP 3-descriptor conv state transfer
- #37310 — N-1 prefill for Mamba P/D disaggregation
Background: The NIXL KV Transfer Workflow
Before diving into the hybrid-model changes, let us briefly recap how NIXL disaggregated P/D works for a standard transformer.
The workflow has four phases:
- Register memory regions — Each worker registers its KV cache tensors with NIXL so they can be accessed via RDMA.
- Create block descriptors — For each registered region, we create per-block descriptors that specify
(address, length, device_id). These descriptors are our unit of transfer: rather than moving entire regions, we transfer individual blocks. - Handshake — When a decode (D) worker first needs to pull from a prefill (P) worker, the two exchange metadata: agent handles, block counts, block lengths, and so on. This is done once per P-D pair.
- Transfer — The scheduler tells D which blocks to pull from P. D maps
block_id -> descriptor_id, issues an RDMA READ, and polls for completion.
For a standard model with M registered regions and N blocks, the descriptor list looks like:
+----------------------------------+
| Region 0: desc_0 ... desc_{N-1} |
| Region 1: desc_0 ... desc_{N-1} |
| ... |
| Region M: desc_0 ... desc_{N-1} |
+----------------------------------+
A block ID b in region r maps to descriptor index r * N + b.
The challenge with hybrid models is that this uniform scheme does not hold: FA layers and SSM layers need different descriptor sizes and different block counts.
The Challenge: FA and SSM State Are Fundamentally Different
In a standard transformer, every layer's KV cache has the same shape: [num_blocks, 2, block_size, num_kv_heads, head_dim] (or a layout variant). All layers share the same block size, same page size, and same number of blocks.
Mamba layers store something very different. Instead of per-token K/V pairs, they maintain a collapsed conv state and a temporal SSM state:
Conv state: (conv_dim, state_len) e.g. (3072, 3) -- bf16
SSM state: (num_heads, head_dim, state_size) e.g. (32, 64, 128) -- fp32
There is no concept of "tokens" in these states — they are a fixed-size summary of the entire sequence history. This means block_size for SSM is effectively 1: each block is a complete state snapshot, not a group of per-token vectors.
Remember: a block is the single unit of transfer here.
The HMA Shared-Tensor Layout
vLLM's Hybrid Memory Allocator (HMA) groups layers by type: all FA layers in one group, all SSM layers in another, and so on. It then pools memory across groups so that layers at the same position in each group share the same physical tensor. This is efficient (blocks are interchangeable), but it means the same tensor is simultaneously viewed as FA blocks by one group and as SSM blocks by another.
Here is the resulting layout for a model like Nemotron-H:
KV Cache Tensor (shared via HMA pooling)
/ \
/ \
Attention (FA) View Mamba View
| |
+-----------------------+ +-----------------------+
| Block 0 | | Block 0 |
| Key | Value | | Conv | SSM |[pad]|
| Block 1 | | Block 1 |
| Key | Value | | Conv | SSM |[pad]|
| ... | | ... |
+-----------------------+ +-----------------------+
The page sizes differ: FA pages are governed by block_size * num_kv_heads * head_dim (*2 for K/V), while SSM pages are conv_state_bytes + ssm_state_bytes.
HMA bumps FA block_size until it's bigger than Mamba's, then pads the Mamba rows (+[pad]) so both groups have equal page sizes in bytes, enabling the shared-tensor scheme.
The problem for NIXL: a single descriptor list with uniform (address, length) entries cannot correctly index both views. We need to register K/V (and similary Conv/SSM) on separate descs to allow indexing K/Vs heads on heterogeneous setups (that is when D TP != P TP).
An FA descriptor for block b points at base + b * page_size with length fa_block_len. A Mamba descriptor for the same block b points at the same base + b * page_size with length conv_size or ssm_size. These differ.
Dual Descriptor Views
Our solution is to register two separate descriptor lists over the same physical memory, concatenated and pointed by a single NIXL transfer handle:
+------------------------------------------------------+
| FA descriptors (M regions x N_phys blocks) |
| |
| Region 0 |
| FA_desc_K[0], FA_desc_K[1], ... FA_desc_K[N-1] |
| FA_desc_V[0], FA_desc_V[1], ... FA_desc_V[N-1] |
| Region 1 |
| ... |
| Region M |
| ... |
| | ^
| --------------------------------------------------- | | num_descs
| | v
| Mamba descriptors (M regions x N_log blocks) |
| |
| Region 0 |
| Mamba_desc_x[0] ... Mamba_desc_x[N-1] |
| Mamba_desc_B[0] ... Mamba_desc_B[N-1] |
| Mamba_desc_C[0] ... Mamba_desc_C[N-1] |
| Mamba_desc_SSM[0] ... Mamba_desc_SSM[N-1] |
| Region 1 |
| ... |
| Region M |
| ... |
+------------------------------------------------------+
Note: Mind that we're using
N_phys/_logto indicate physical and logical blocks respectively. You can assumeN_phys=N_log=Nand refer to the next section for when that's not the case.
Note: the Mamba section above already reflects the conv-state decomposition into x, B, C sub-projections, explained in The 3-Descriptor Conv Transfer below. For homogeneous TP, these simplify to two sub-regions (Conv, SSM).
The FA descriptors occupy the first num_descs = M * N_phys slots. The Mamba descriptors follow immediately after. Block ID mapping becomes:
if is_fa_group:
desc_id = region_id * N_phys + block_id
else: # mamba group
desc_id = mamba_region_id * N_log + block_id + num_descsPhysical vs. Logical Block Sizes
A second complication arises from attention kernel requirements. Backends like FlashInfer require a specific physical block size (e.g., 16 tokens) that may differ from the logical block size set by the user or computed by HMA.
For standard models, this is handled by a simple ratio:
physical_blocks = logical_blocks * ratio
ratio = logical_block_size / kernel_block_size
For hybrid models, this ratio applies only to FA layers. SSM layers have no "token" dimension to split, so they always use logical_blocks directly. This means the FA and Mamba sections of the descriptor list use different block counts:
FA section: M regions * N_phys blocks (N_phys = N_logical * ratio)
Mamba section: M regions * N_logical blocks
This is tracked via the _physical_blocks_per_logical field, which is computed per-engine (since P and D may have different ratios when their TP sizes differ). The block-ID-to-descriptor-ID mapping in _get_block_descs_ids uses the appropriate stride depending on whether it is resolving an FA group or a Mamba group.
The 3-Descriptors Conv Transfer
For homogeneous TP (P and D use the same --tensor-parallel-size), transferring SSM state is straightforward: each D rank reads the corresponding conv + SSM block from the matching P rank.
Heterogeneous TP makes this harder. Consider P_TP=1, D_TP=4: four D workers must each read their shard of the conv and SSM state from a single P worker. The SSM temporal state is sharded along the heads dimension, which is the first axis — so slicing is trivial. But the conv state is structured as:
Conv state = [x | B | C] where x, B, C are sub-projections
^ ^ ^
| | |
intermediate_size / TP groups_ss / TP groups_ss / TP
With the standard SD layout (state_len, dim), these sub-projections are interleaved in memory. A D worker wanting only its portion of x would need to gather non-contiguous bytes — impractical for zero-copy RDMA.
The DS Layout Solution
We require the DS layout (dim, state_len) for conv state (set via VLLM_SSM_CONV_STATE_LAYOUT=DS). In this layout, each sub-projection's data is contiguous in memory:
DS layout within one page:
|--- x (x_bytes) ---|--- B (b_bytes) ---|--- C (b_bytes) ---|--- SSM ---|
Each D rank can now read its slice of x, B, and C with three separate, contiguous RDMA reads — hence "3-descriptor transfer" (we still only issue one NIXL READ).
For heterogeneous TP, the remote_conv_offsets method computes where each D rank's slice lives within the P page, accounting for the TP ratio.
This gives us 4 descriptor regions per Mamba layer (x, B, C, SSM) instead of the 2 regions (Conv, SSM) used in the homogeneous case. The trade-off is a larger descriptor list, but the RDMA transfers themselves remain efficient contiguous reads.
No extra in-memory staging buffer is allocated on either GPU. No data reshuffling is needed on either side.
Note: We have not measured noticeable regressions in kernel performance when using the DS layout for regular colocated setups. We may update the standard layout to be DS at all times in future versions.
Zero-Overhead: No Extra Buffers, No Permutation
A simpler alternative would be to transfer the entire conv state to each D rank and then permute/slice it locally into the right shape. But for Mamba, we deliberately avoid this approach:
- No staging buffer — Permuting on D would require allocating a temporary buffer the size of P's full conv state on every D worker. With models like Nemotron-H, conv state per block is already significant (
3 * 3072 * 2 bytesin bf16). Multiplied across thousands of blocks and all Mamba layers, this overhead adds up and chips space that could be used for KV cache. - No post-transfer reshuffling — With the DS layout, each D rank reads exactly the bytes it needs, directly into their final destination in the KV cache. There is no post-transfer kernel to rearrange data. The transfer completes and the state is immediately usable.
- Transfer only what you own — Each D rank transfers only its
1/TPshare of the conv state, not the full state. ForD_TP=4, this means 4x less data per rank compared to the "transfer everything, slice locally" approach. - Skip HMA padding — Recall that HMA pads SSM pages so they match FA page sizes. The Mamba descriptors are sized to the actual
conv_bytes + ssm_bytes, not the padded page size. This means we never transfer the padding bytes over the wire — only the real state. For models where the padding is substantial (e.g., when FA page sizes are much larger than the raw SSM state), this can meaningfully reduce transfer volume per block.
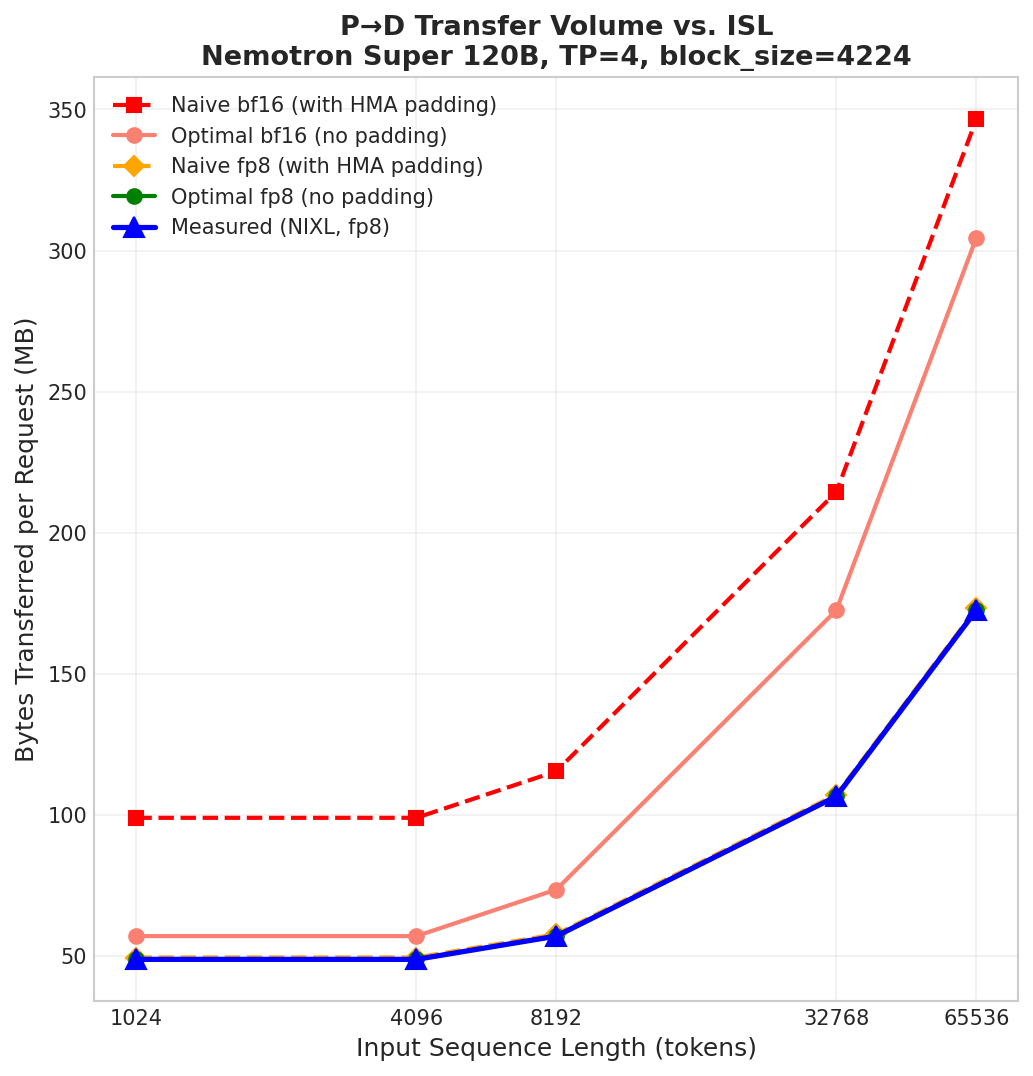
The figure below validates the zero-overhead transfer optimizations on Nemotron Super 120B at TP=4 (FA block_size=4224, as set by HMA). For each KV cache dtype (bf16 and fp8), we compare a Naive baseline - which transfers full HMA-padded pages for Mamba blocks - against Optimal approach which transfers only the actual conv + SSM bytes, skipping all HMA padding and/or auxiliary buffers. We first validate that our approach matches Optimal as reported by transfer metrics.
For fp8, the FA page size is smaller (1 byte per element vs 2), so the padding is negligible in this configuration. We then show the savings on a bf16 setup, where our approach eliminates ~50 MB of unnecessary transfer per request.
Since Mamba state is a fixed-size per-request summary, transfer size scales with the number of FA blocks as ISL increases.
Putting It Together: Nemotron-H Example
Let us walk through a concrete example: serving nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 with disaggregated P/D at TP=2.
Model structure: 52 layers total, alternating between Mamba and FA. HMA groups them into 5 groups (4 Mamba, 1 FA). After memory pooling, this yields 6 shared KV cache tensors.
KV cache layout:
FA layers: [num_blocks, 2, block_size=400, 4, 128] # K/V with HMA-inflated block_size
SSM layers: [num_blocks, 3, 3072] (conv) + [num_blocks, 48, 64, 128] (ssm)
HMA pads the block sizes so both views have the same page size in bytes. The kernel (FlashInfer/FlashAttention) may further subdivide FA blocks, creating a physical/logical ratio.
Descriptor registration:
- The 6 shared tensors are registered as NIXL memory regions (same as dense models).
- FA descriptors are created for all 6 regions x
N_physblocks, indexing K and V separately. - Mamba descriptors are appended: 6 regions x
N_logicalblocks, with 4 sub-regions each (x, B, C, SSM) for the 3-descriptor transfer.
Transfer flow:
- P finishes prefill. The scheduler assigns block IDs per group:
[[fa_block_ids], [mamba_block_ids_g0], [mamba_block_ids_g1], ...]. - D receives the block IDs and maps them to descriptor indices: FA blocks use the standard
region * N + block_idformula; Mamba blocks add thenum_descsoffset and useN_logicalstride. - D issues a single
make_prepped_xferREAD with both FA and Mamba descriptors, then polls for completion. - On completion, D notifies P so it can free the blocks.
The entire transfer is a single async operation from D's perspective. No intermediate buffers, no data reshuffling.
Performance
We benchmark disaggregated P/D against co-located serving on 8x H200 GPUs connected via NVLink. The model is nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-FP8, a recent 120B LatentMoE hybrid architecture with interleaved Mamba2 and full-attention layers.
- Co-located baseline: single instance, TP=8, all 8 GPUs.
- Disaggregated P/D: 1 prefill instance (TP=4, 4 GPUs) + 1 decode instance (TP=4, 4 GPUs), same total GPU count.
We sweep concurrency from 8 to 256 concurrent users and plot output throughput per GPU against per-user output token rate (Interactivity). The workload uses ShareGPT as test dataset.
All runs use a very high warmup value to ensure KV cache gets "scrambled" in order to avoid the initial performance boost you get when request blocks happen to be allocated contiguously. This reflects regular long-running use more accurately. Once can also verify it by checking a constant number of descriptors is reported in the metrics (over a full dataset sweep).
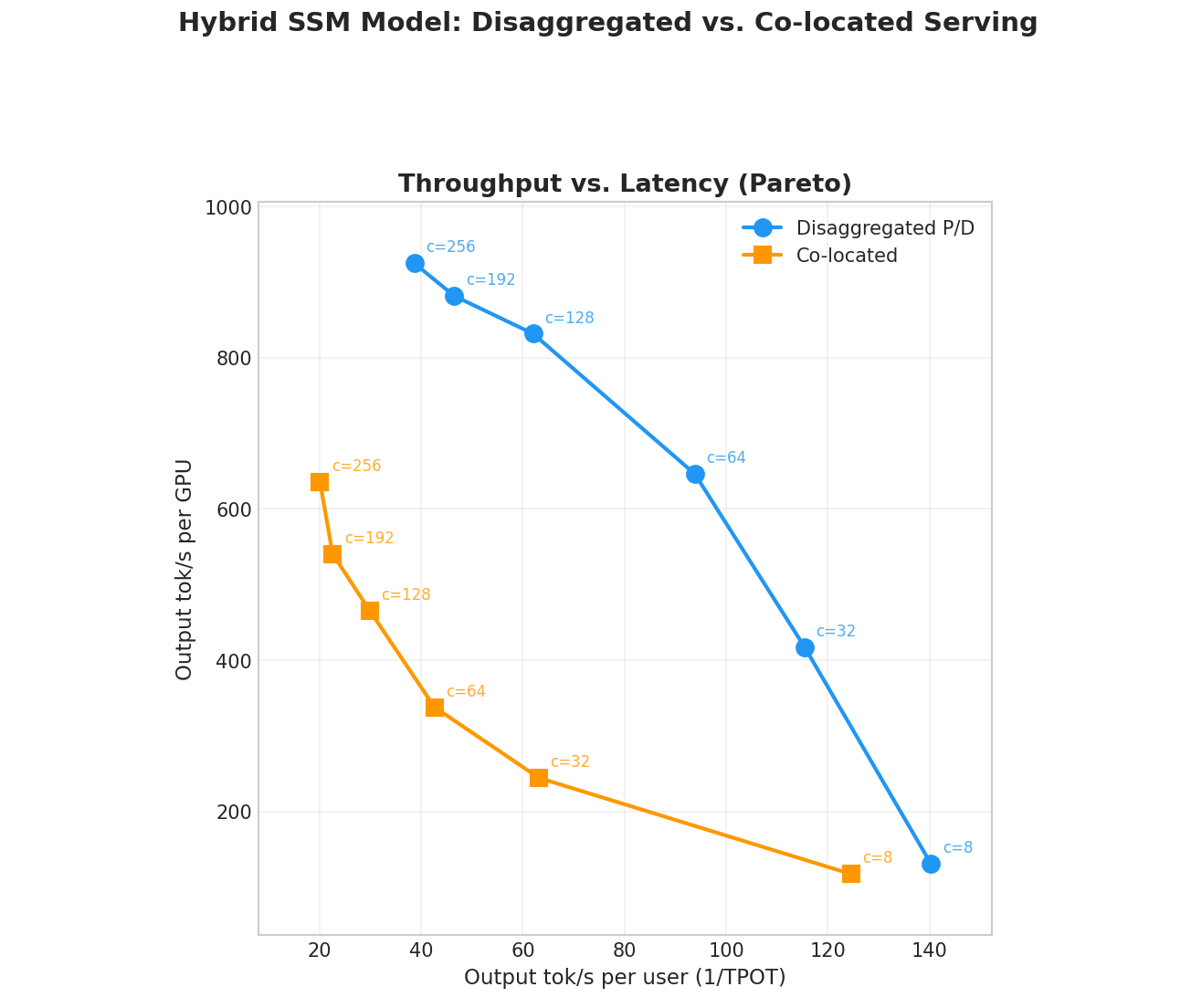
The results show the same pattern observed with disaggregated serving for standard transformer models: disaggregated P/D Pareto-dominates the co-located baseline at higher batch sizes. By isolating decode from prefill interference, the decode instance can sustain larger batches without stalling, yielding significantly higher output tok/s per GPU at high concurrency.
Getting Started
To run a hybrid SSM model with disaggregated P/D:
# Prefill instance
VLLM_SSM_CONV_STATE_LAYOUT=DS vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.85 \
--trust-remote-code \
--max-model-len 8192 \
--block-size 128 \
--no-disable-hybrid-kv-cache-manager \
--kv-transfer-config '{"kv_connector":"NixlConnector","kv_role":"kv_both"}'Note: DS conv state layout set
VLLM_SSM_CONV_STATE_LAYOUT=DSis required for heterogeneous TP, but not necessary otherwise.
Limitations and Future Work
- Mamba1 models: The 3-descriptor conv transfer currently supports Mamba2 only. Mamba1's SSM temporal shape
(intermediate_size // tp, state_size)does not allow reconstructingintermediate_size, which is needed for the conv decomposition. Similarly, GDN support (Qwen3.5+) is listed in the disaggregated roadmap - Speculative decoding: Interaction between SSM state transfer and speculative decoding has not been extensively validated.
- Mixed block sizes with HMA: Different block sizes between P and D (
block_size_ratio > 1) are not yet supported when HMA is enabled.
Acknowledgments
Thomas Parnell (IBM Research), Roi Koren (NVIDIA)